
Introduction
ArteraAI was founded on the idea that cutting edge technology can be used to completely transform the medical field. From the beginning, we knew that our application would be using predictive Artificial Intelligence to personalize care for people suffering from prostate cancer. We wanted our application to be a game changer- truly the best in the world. To support that ambition, ArteraAI Engineering team was determined to provide the supporting infrastructure to accomplish (and even exceed) these goals.
The Planning Stage: Infrastructure Strategies and Goals
We knew from the outset that this was going to be a cloud-first operation. After all, cutting edge applications need cutting edge tools. We also knew we needed our environment to be highly secure, highly performant, and easy to monitor and manage. After a careful evaluation of the major cloud providers, ArteraAI selected Amazon Web Services (AWS) as our platform. We decided upon a few bedrock design principles, and got to work on the environment.
Security
The number one priority for ArteraAI Engineering is data security. To protect our customers data, the infrastructure needed to be highly secure. Responsible data stewardship is not just the right thing to do- it’s also the law. ArteraAI operates in a regulated industry, and we knew we needed to withstand the highest levels of scrutiny. This philosophy has been embraced throughout the company, and our security efforts have been a great success. ArteraAI is officially HIPAA compliant, and SOC 2 Type II certified. You can learn more about these certification efforts here, and here.
Environmental Isolation
The overall ArteraAI AWS environment has been broken up into 6 AWS Organizational Units (or “OUs”). This was done based on AWS best practices, and groups related accounts together for security and auditing accountability. The OUs that we use are organized like this:
- Security and Audit
- Networking
- Production
- Development
- Sandbox
- Collaboration
These smaller segments make it easy to understand what the purpose of an environmental segment is. This clarity helps keep each OU as tightly focused as possible, resulting in more efficient performance and easier auditing and management.
Authentication
We centralized all of our user accounts into the AWS SSO product, which oversees account authentication across all of our OUs. This ‘single source of truth’ enables us to tightly control who has access to what and disable accounts immediately if our logging and alerting mechanisms show that there is any cause for concern.
Access is controlled at ArteraAI using AWS IAM Roles. Creating roles has allowed us to sculpt temporary access capabilities that can then be granted to users on an as-needed basis. This role-based access control methodology means that users only ever have the permissions they need to perform a specifically defined task. All of this access is defined in policies that are regularly audited to ensure rigid adherence to the highest levels of information security regulations and best practices.
Network Architecture
Communications in our environment are tightly controlled. We required full control over every request, regardless of whether traffic is coming from the internet, or from within our own various Accounts and VPCs.
ArteraAI’s AWS networking environment is set up so that there is only one ingress/egress point. This single internet gateway connects our environment to the internet, but does so through an AWS Network Firewall. Since all traffic must go through this stateful firewall, all traffic can be inspected, and accepted/denied based on our stringent firewall rules. If traffic is allowed to pass through, it then connects to whichever OU environment it needs to.
While there are several valid ways to connect the OU environments together, we ultimately decided to utilize the AWS Transit Gateway product. Transit Gateway is an industry-standard method of managing and supporting connectivity between any number of VPCs (and even external or on-premises connections). Transit Gateway is the AWS preferred method of connection management. It is flexible and powerful. Transit Gateway ensures that the only traffic that can flow between OUs is the traffic that ArteraAI Engineering has approved, thus providing an additional layer of security along with the Network Firewall.
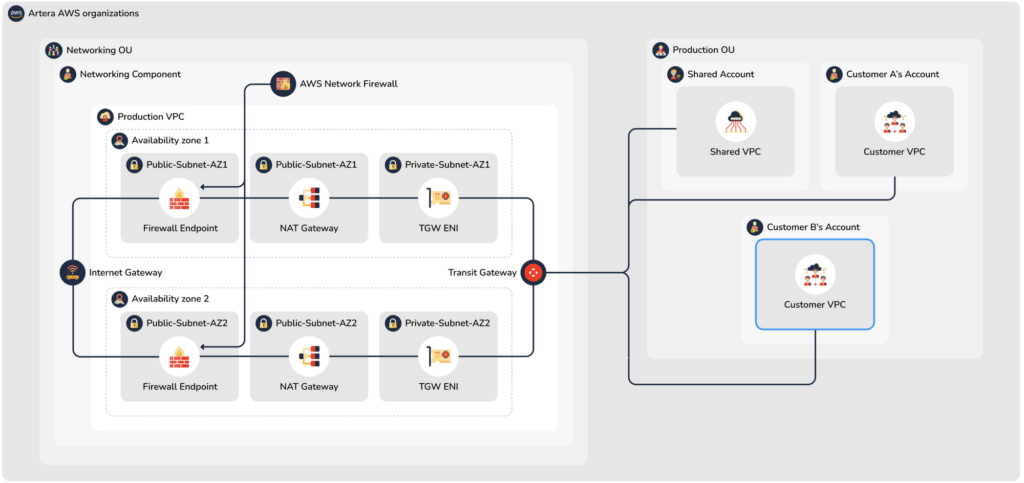
Figure 1 – High-level diagram showing connections between OUs using the Transit Gateway
Application-Level Security
ArteraAI Engineering does not just work to secure the infrastructure- we work hard to keep the application itself secure as well. We use multiple tools to actively scan our code for vulnerabilities, as well as monitoring the security of our Kubernetes deployment. Some example products we currently use for application security include Snyk Code and Snyk Container (for code scanning and individual container security), and Fairwinds (for Kubernetes cluster security, governance, and optimization).
We also use Lacework to help secure our infrastructure. Lacework is a valuable tool in our security arsenal in that it helps protect our entire environment. It ingests and analyzes data from both the underlying infrastructure (the overall AWS environment) and the application level (Kubernetes) to detect anomalous behavior and provide a single consolidated view of our cloud environment. This holistic view saves time, eliminated the need for a number of other tools, and helps ArteraAI Engineering monitor and manage security across our entire cloud deployment.
High Availability
We also want to ensure high availability and disaster recovery are in place for our environments. The work we do for our customers is critical, and it is critical that they always have access to our applications (and, by extension, their data). As the expression goes, ‘hope for the best, but prepare for the worst.’
To do this, we embraced the industry-leading capabilities of the AWS cloud environment. For High Availability, we designed our applications to take advantage of AWS Availability Zones. These Availability Zones (or “AZs”) are internally isolated and redundant environments within each AWS Region. Our infrastructure spans multiple AZs, (us-west-2, for example, has 3 AZs). This means that even if there is a catastrophic loss AZ 1, for example, AZ 2 would still be available to completely support our production environment.
Disaster Recovery
Our multi-AZ deployment design provides protection against localized failures. But we still need protection against a full Region failure. (While outages that cause a full region failure are exceedingly rare in the AWS ecosystem, it has happened.) After looking at the various options we decided to go with what AWS defines as a “warm standby” strategy, with a recovery environment built out in the us-east-2 region.
The warm standby strategy is the next best thing to a complete mirror of production. We always have a live copy of our secured production data in the DR environment, along with a fully set up and deployed copy of our normal environment that runs out of us-west-2. The only difference is that 1) the DNS records all point traffic to production, and 2) we run with a reduced number of systems in DR. This reduced capacity allows us to save on operating costs while still being able to process requests.
In the event of an emergency, the DNS entries would be switched over, and the full capacity of servers and services would be brought online. Once these two things are complete (a matter of mere minutes), our Disaster Recovery plan would be complete. The DR environment in us-west-2 would be accessible at the same network addresses and our applications delivering the same high-quality performance that our customers rely on.
Conclusion
Leadership at ArteraAI challenged us in Engineering to build an infrastructure that was secure and simple to understand, but also powerful and resilient. Simply put, we succeeded in this task. We have an environment that is performant and protected from both major and minor outages, and we have passed both HIPAA and SOC 2 Type II compliance audits that confirm our security is state of the art. It has been an exciting time here at ArteraAI Engineering, and we can’t wait to see what’s next.
Come work with us!
Thank you for reading. One last thing: we are a fast-growing company, and we are hiring. Are you a cloud-native engineer that thrives in dynamic environments? Do you have AWS experience? Do you like working on Machine Learning problems at scale? If so, we might have a position for you! Please take a look at our open roles, and don’t hesitate to reach out if you have any questions.
Related Articles

An Introduction to ArteraAI’s Cloud Infrastructure
Introduction ArteraAI was founded on the idea that cutting edge technology can be used to completely transform the medical fi [...]

How AI can support the American Cancer Society’s IMPACT...
Andre Esteva, Co-founder and CEO of ArteraAI, discusses how AI can support the ACS’ IMPACT initiative and other possibilities [...]